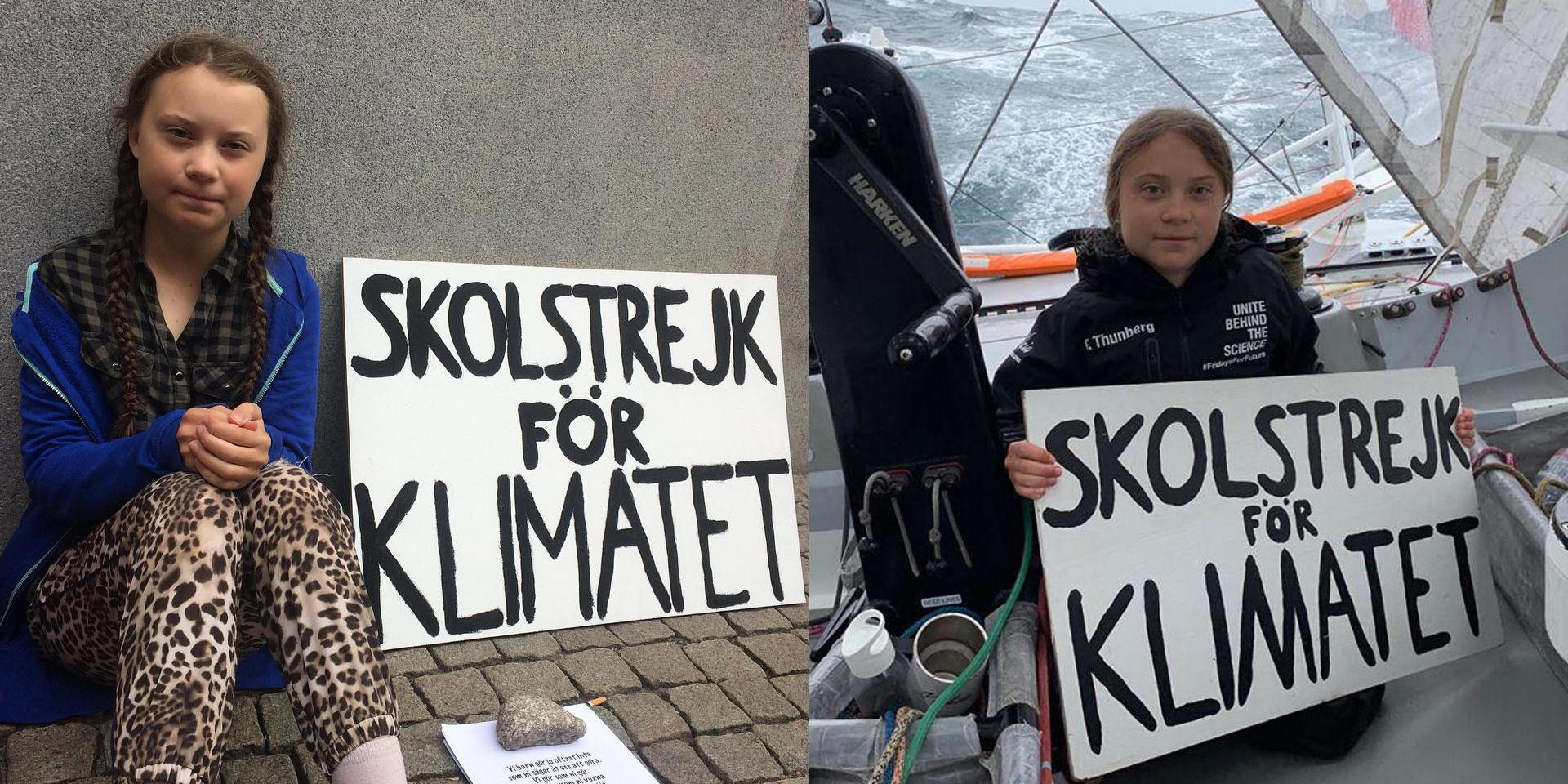
We’re at a pivotal time for our species and our planet. The world is facing an existential crisis and we must act. And so, this September 20th, we will be joining the young climate strikers and millions of others in a Global #ClimateStrike on the streets and demand an end to the use of fossil fuels. We demand climate justice for everyone.
TLDR;
-
Our site will “go green” with a digital strike on Sept. 20, 2019.
-
There will be a banner at the bottom of our site leading up to the event.
-
There will be a full banner across the entire website on Sept. 20th.
-
Our team will be on strike that day and participating in a Global Climate Strike march.
Why?
Our planet—our house—is on fire. We’re in the midst of the 6th mass extinction. In the IPCC report, scientists tell us that we have 420 gigatons of CO2 budget left to have a 67% chance to keep global warming under control (below 1.5C degree of warming). Beyond that, we face a tipping point that will put unbearable pressure on human civilization. To make the matter worse, by many accounts, the IPCC is considered to be very optimistic. Our CO2 budget to achieve the goals set out in the Paris Agreement may already be depleted. The melting of the Greenland ice sheets we saw this summer was only supposed to happen by 2070. And storms like Hurrican Dorian, which turned the lives of countless people upside down, are being intensified by climate change. A hotter ocean means stronger storms, a rising sea means worse flooding, a hotter atmosphere means more rain. These storms are only expected to get worse and more frequent if we continue to let the climate break down.
Today, we’re on track to blow that CO2 budget. We’re releasing about 42 gigatons of CO2 per year. And despite all the efforts of the past 30 years from many activists and governments, emissions are still rising. The emissions need to stop. We need to unite behind the science, recognize the existential threat that climate change is, and act.
This digital climate strike is an effort to raise awareness of what is happening and communicate that we can’t wait any longer. We have to act quickly and decisively because we’re running out of time. We need massive mobilization for the climate. We are calling on leaders to take the measures required to safeguard the conditions for a dignified life for everybody on earth.
Communication platforms have a huge role to play in this fight. We were tremendously inspired by Greta Thunberg, a Swedish climate activist, when she sat in front of the Swedish parliment a year ago to stike for the climate (and each Friday since) and when she gave her poignant speech to UN Secretary-General António Guterres at COP24. We heard her message because of tech. And we were able to follow her ongoing strikes and her carbon-free transatlantic journey thanks to tech. Tech has the power to communicate in a way no other platform ever has. It has the power to end the climate crisis. So we’re answering Greta’s call to action, and the call of the scientists and other activists, to do something. To act.
We will be joining the Global Climate Strike in Denver, CO on Sept. 20th. And we’ll continue to fight for our future, this Friday and every day after.
What can you do to help?
-
Listen to the science.
-
Ask your company to join the digital strike for climate.
-
Take time to contribute to one of the movements for the climate, such as Sunrise Movement, Extinction Rebellion, Fridays for Future, 350.org, Citizens’ Climate Lobby, or one of the many other organizations fighting for our future. Your voice as member of the tech community can make a real difference.
-
If you can afford to, take time off or a sabbatical to join one of those movements full force.
-
Get your company to allow you to participate in one of these movements during your working hours. An example of a company doing this is Atlassian. They were amoung the first tech giants to push employees to join the strikes, which then prompted many other major tech companies to do the same.
-
Donate to one of the aforementioned movements on OpenCollective: https://opencollective.com/search?q=climate. OpenCollective is participating heavily in the Climate Strike.
See you on the streets.
Dan Allen and Sarah White, cofounders of OpenDevise
Attribution
This post was adapted from a post made by Pia & Xaviar at OpenCollective, who are demonstrating tremendous leadership in the cause for climate action.








